Applications of Computational Linguistics,
WS 01/02
Answer Extraction
Alexander Deubelbeiss, February
1, 2002
An answer extraction system: ExtrAns
An answer extraction system accepts a question formulated in natural language
as its input. The answers are not generated by the system from a
"knowledge database" but extracted from a body of human-formulated
texts. These texts typically belong to a highly restricted domain but were
originally written for other humans in syntactically unrestricted language.
Aim: to provide better precision (relevance of results
to the query) while maintaining the recall (completeness of results)
of Information Retrieval methods that do not use NLP, without the cost
and difficulty of developing a language-understanding question-answering
system or of porting an existing one to a new domain. According to the
developers of ExtrAns, answer extraction is well suited to medium-sized
static corpora.
The answers are not entire documents but only those parts that
seem to provide a direct answer to the specific question the user asks.
All questions are treated separately: the system stores no information
about earlier questions, and it can't make sense of elliptical follow-up
questions ("Which of these commands is suitable for text files?"). Answer
extraction aims to supply all relevant answers (which may contradict each
other) to each question, not to create the impression of having a conversation
with a computer.
ExtrAns(University of Zürich Institute of Computational
Linguistics) extracts its answers from Unix man (=Manual) pages, i.e.,
the documentation of a computer operating system's commands. A new version
that uses the (substantially larger) technical manuals of the Airbus 320
as its data is currently being developed.
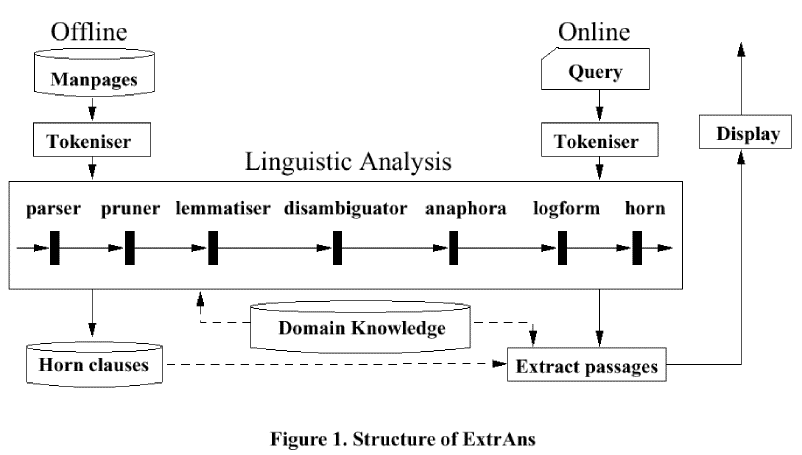
ExtrAns converts its source data into "logical forms", a representation
of both the syntactic structure and the semantic content of a sentence.
This explains why it is useful to have a static corpus: that way, the conversion
needs only be done once. Queries are subjected to the same treatment. Then,
the source text database is searched for a sentence with a logical form
that is equivalent to the logical form of the query.
Problems:
-
Domain-specific language: The system needs to distinguish, for instance,
between the command eject and the common verb eject; between
the system's printing a warning message on the screen and the user's
printing
a document on paper; between filename as a placeholder in a command
description and the word filename etc.
-
Ambiguity: Not all ambiguities can be resolved, neither in the source text
nor in the query. ExtrAns simply stores the different interpretations as
possible alternatives and then uses them to score the accuracy of its results:
the more interpretations of a source text sentence match an interpretation
of a query, the higher that source text sentence is scored. This score
is translated into a highlighting colour in which the answer sentence is
displayed. The alternative interpretations themselves have a probability
score from the syntactic disambiguation process, which uses empirical rules
to mark certain syntactic structures as more likely than others.
-
Incomplete analysis: Since the source text is unrestricted language, the
parser often fails to analyse a sentence completely; in other cases, the
source text contains incomplete sentences (e.g. in headings). With the
specific data representation and matching methods used in ExtrAns, partial
analyses can still be matched to their counterparts in more completely
analysed sentences. In those extreme cases where no structure whatsoever
is found, the individual part-of-speech-tagged content words are used as
search terms for a string-match search.
-
Synonymy and hyponymy: if a search does not return a minimum number of
results, the system will extend its search by allowing first synonyms and
then hyponyms for certain search terms. For this purpose, a special domain-specific
dictionary has been developed for ExtrAns.
-
Performance: ExtrAns uses a traditional Information Retrieval search to
pre-select the pages to search in: Only the logical forms of documents
containing the content words in the query are selected for the actual NLP-using
search procedure.
References
Berri, Jawad; Mollá Aliod, Diego; Hess, Michael. Extraction
automatique de réponses: implémentations du système
ExtrAns http://www.ifi.unizh.ch/CL/berri/taln98.ps.gz,
retrieved in January 2002
Hess, Michael. Mixed-Level Knowledge Representations
and Variable-Depth Inference in Natural Language Processing. http://www.ifi.unizh.ch/CL/hess/ijait.ps.gz,
retrieved in January 2002.
Mollá Aliod, Diego; Hess, Michael. On the Scalability
of the Answer Extraction System "ExtrAns". http://www.ifi.unizh.ch/CL/molla/klagenfurt.ps.gz,
retrieved in January 2002
Mollá Aliod, Diego; Berri, Jawad; Hess, Michael.
A
Real World Implementation of Answer Extraction.
http://www.ifi.unizh.ch/CL/hess/nlis.ps.gz, retrieved in January 2002
The ExtrAns project
Information about the
project
Demo